At Man Group, managing data is at the heart of what we do and the data structure our quants and researchers work with most often is the DataFrame. As an active investment manager looking after billions of dollars in assets, it’s crucial that we have the ability to store and process DataFrames of all shapes and sizes; from tiny pieces of metadata to giant time-series, with excellent performance and built-in reliability. We realised 10+ years ago that we needed a database that puts the DataFrame at the heart of its data model, and that is what we’ve built with ArcticDB.
ArcticDB is designed to take advantage of two modern developments in the world of databases:
Firstly the availability of cost-effective, high-performance storage both in the cloud and on-premises.
Second, the renewed interest in immutability as a means of ensuring horizontal scalability without performance degradation; providing time-travel over previous versions; and, guaranteeing the availability of critical data.
ArcticDB is based on key-value storage — rather than local disk — and this means we need to think carefully about what our keys look like, both to avoid naming conflicts and to ensure that the keys are meaningful.
We decided on multi-part, ‘structured’ keys that contain different fields describing the version; start and end index points, timestamp and so on. One advantage of using structured keys is that many operations can be performed just by looking at the key contents. This means avoiding the cost of retrieving objects altogether; for example in implementing the parallel write functionality that makes it possible to write many DataFrames in parallel and then combine them into a single entity. This means we can use the start and end index from the key to work out whether the individual DataFrames have overlapping indexes and need to be merged, or can be inserted into the index directly.
Similarly, we can scan an index and — just by reading the keys contained in it — determine whether the objects it references are optimally sized for performant reads, or if we need to perform splitting or compaction.
We soon realised that a set of these structured keys would fit perfectly inside a DataFrame. The effect was that we could write a single type of object to the storage and use it for both user and system data.
This is a common pattern in database design, where a database uses its fundamental type (whether tables, documents or graphs) for storing metadata, and for good reason: implementers can concentrate on making a single structure as performant as possible, and improvements to data-processing capabilities such as filtering benefit both user and system performance alike.
A DataFrame with rows representing the keys of other objects makes it possible to create different kinds of structures in the storage (such as B-trees, LSM trees, or linked lists), and these are the fundamental data structures from which ArcticDB is composed.
The second design decision we made was to make all the critical structures persistent, meaning that no matter how they are modified they efficiently preserve all their previous incarnations.
This has multiple benefits:
It’s impossible to corrupt data if you don’t modify it;
users are protected from bad writes at the application layer (as it is always possible to restore a previous good version); and;
the complicated apparatus of locking and coordination required to ensure that simultaneous modification of the same block doesn’t create data races can be simplified, and in many cases removed entirely.
Traditional distributed databases spend a lot of time passing copies of the same data around to insure against hardware failure. But in the era of replicated block storage, it is unnecessary to duplicate this effort in the database layer. Since data is only added and removed, not modified, we no longer need an always-on server component to guarantee consistency. Given that we can defer the responsibility for managing disk failure to the storage, we are able to manage without a server process for client operations.
This dramatically reduces support costs and increases resiliency, since there is no longer reliance on a single process that has to split its time between performing housekeeping tasks — like compaction and defragmentation — and being continuously available to service client requests.
As long as a client can connect to the storage, data is always available. A separate background process tailing a write-ahead log replicates between data centers to provide backup and disaster-recovery capabilities, so there is always an up-to-date storage available for a client to talk to.
Database Layers
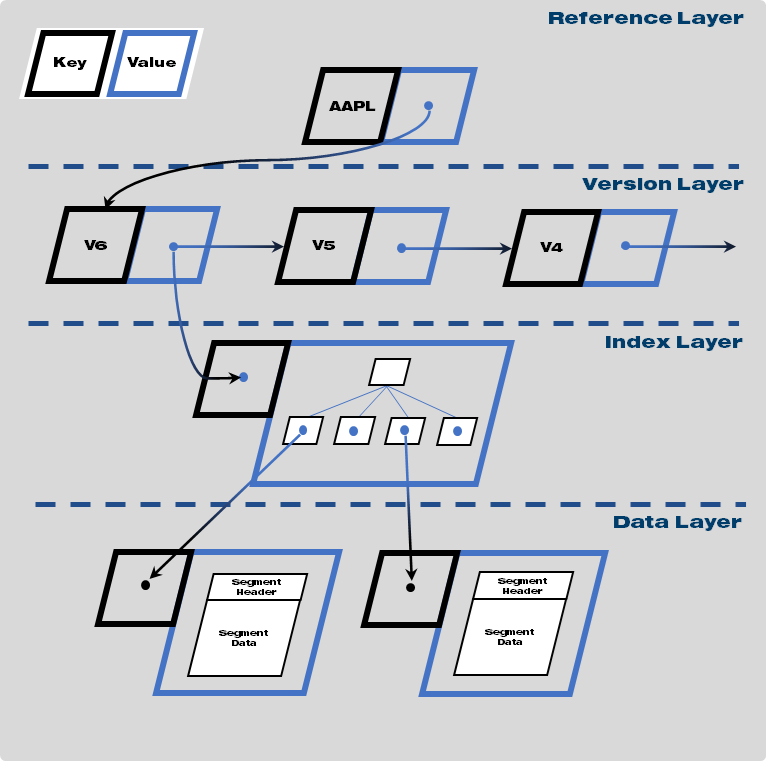
The database architecture is composed of four layers; at the bottom level data and index DataFrames store user data and allow for fast sub-selection of data by time range, column and secondary characteristics. Above this is the version layer, where information about the available data is journaled and subsequently compacted. On top of this is a mutable layer of tiny pointer objects, which accelerate the process of finding a particular version by providing a deterministic key for the head of each version list.
These layers are always written bottom-up, so that all the components of an object are fully available before the pointer objects are updated and the new version becomes available. As no data is shared between different named objects (what we refer to as a symbol), tasks can be parallelized across symbols with perfect scalability up to the capacities of the storage and network.
We hope you have enjoyed this deep-dive into how ArcticDB structures data on disk. This has provided us with performance improvements across the business, and we’re confident that it could provide the same for others.
Our Journey Creating ArcticDB: Solving the Challenge of DataFrames at Scale
ArcticDB
Apr 14, 2023

Aug 19, 2025
Unlocking the Winning Formula: Sports Analytics with Python and ArcticDB
Discover how Bill James' famous Pythagorean Won-Loss formula predicts team success. This deep dive uses ArcticDB to uncover key insights for winning.

Mar 21, 2025
Our Man Group case study: Generating alpha and managing risk at petabyte scale using Python.
This blog explores how ArcticDB is transforming quantitative research by overcoming the limitations of traditional database systems.

Elle Palmer