The 1 Billion Row Challenge (1BRC) on ArcticDB
ArcticDB
Aug 22, 2024

The Challenge
The 1 Billion Row Challenge was a tech competition that was run in January 2024.
The objective was to read and aggregate a csv file, each line of which contained a temperature for a particular weather station. The code for this was to be written in Java
The goal was to output the min, mean and max temperature for each weather station.
A sample file was included in the project that contained data for 413 weather stations. Code was included to generate random data for 10,000 weather stations with 1 billion rows.
Lots of entries were submitted. The winning entry took just over 1.5 seconds to complete the challenge. There were a range of entries taking up to 4 minutes.
You can read more about the original challenge here https://github.com/gunnarmorling/1brc.
Meeting the Challenge with ArcticDB
We decided to keep to the spirit of the original challenge but we adapted it to use ArcticDB to do the leg work.
Assumptions
We will use Python and ArcticDB for the data handling and processing
We will use lmdb as the ArcticDB backend, which stores the data on the local file system
We don’t include the time of creating and writing the data in the challenge time — just reading and aggregating — the same as the original Java test.
Steps
Create an ArcticDB object store and library
Generate the data and write it to a symbol in the library
Query we using aggregates min, max and mean for each city
The data is aggregated using the query_builder parameter as part of the read
This will use C++ threads to concurrently process the IO and CPU intensive parts of the tasks
The output is the aggregated data
Summary
This is all done in less than 50 lines of easy to understand Python code
Links to the notebook and relevant docs to explain how to use ArcticDB are available at the end of the article
Most of the code is setup and data creation
The actual read and aggregate is only 2 lines of code
How Does it Perform?
Running on a Dell XPS15 laptop with 14 cores and 64GB of RAM, the challenge runs in 7.2 seconds.
Running on a more powerful machine with 64 cores and 512GB of RAM, it runs in 4.1 seconds.
This is the equivalent of the “10k” challenge, the comparable results from the challenge are here 1brc 10k results. The results range from 3 seconds to 23 seconds.
So we have created a solution that is competitive with hand optimised Java using only a few lines of high-level Python.
Try looking at the code in the 1BRC github for the solutions that ran fastest in the challenge and you will soon realise that this kind of code can only be written by someone who is an expert in low-level code optimisation and even for an expert this kind of coding requires many iterations of profiling and improving to get the best performance.
In order the illustrate how ArcticDB can make use of the multiple cores available, we ran with various numbers of threads. The results are in the table below
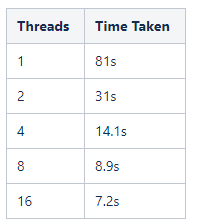
You don’t need to worry about this. ArcticDB can detect how many cores your machine has and will use all of them unless you restrict it as shown in the notebook.
Another version, modified to chunk the read/aggregate step to fit in the available memory, runs in 2 minutes on the free google colab. You can find that at the end of the notebook link at the bottom.
During the testing of this challenge, we discovered a few areas where we can in future improve the performance of the C++ engine further. We expect the speed to increase in even further in future.
Conclusion
We are pleased that using ArcticDB we were able to achieve performance approaching that of well written hand optimised code.
Please take these results as they are intended — we are not claiming to have solved the challenge itself but rather to have tackled the same problem using ArcticDB.
We have not tuned the performance beyond the basics. We wanted to keep the code simple and readable to show how easy it is to use ArcticDB to efficiently solve a wide range of problems.
How Can I Find Out More?
Links to
Notebook: https://docs.arcticdb.io/dev/notebooks/ArcticDB_billion_row_challenge/
Docs: query_builder, read, Home Page
Website: https://arcticdb.io/

Aug 19, 2025
Unlocking the Winning Formula: Sports Analytics with Python and ArcticDB
Discover how Bill James' famous Pythagorean Won-Loss formula predicts team success. This deep dive uses ArcticDB to uncover key insights for winning.

Mar 21, 2025
Our Man Group case study: Generating alpha and managing risk at petabyte scale using Python.
This blog explores how ArcticDB is transforming quantitative research by overcoming the limitations of traditional database systems.

Elle Palmer