Finding value in data for quant and financial data analytics isn’t just about taking data from its raw form and transforming it into a usable format. In fact, in modern financial analytics those transformations are just a thin slice of the process, before the data science really starts.
British mathematician Clive Humby famously remarked back in 2006 that “data is the new oil”, and we think that holds true today. However, a contemporary interpretation is that data is more akin to a renewable commodity; in that it’s continually re-used, shared and renewed throughout the data value chain. The best performing systems today are the ones that optimise for the sharing, re-use and renewal of data between technologies and people.
Quant and financial data analytics practitioners can be likened to modern-day artisans; much like a watchmaker whose workshop is equipped with specialist implements for the creation of intricate timepieces, quant researchers and engineers need to carefully consider the tools at their disposal in order to build complex systems that bring together data, technology and people.
Selecting the right toolkit to build quant systems:
What are the most important factors to consider when building the toolkit?
Select the right solution for the problem: A highly specialised problem likely needs a highly specialised solution. It’s possible to use a sledgehammer to crack an egg, but is it the best way?
Choose interoperable: Tools need to be adaptable and equipped to move with the waves of change of organisations, methodologies and integrate with seamlessly with existing systems.
Retain the ability to scale efficiently: In modern data science environments, tools should scale right through from individual users to production-heavy systems.
Prize invisibility: The best tools are those that fit seamlessly into consciousness; there should be low barriers to learning and use.
How we leverage Python and Open Source for financial data science
We are a technology team that believes in open source. Several years ago, we decided to centre our front office analytics in Python. At that time, Python was emerging as a growing open-source language. Its readability and ease of integration with other technologies made it an ideal choice for the types of workflows we run; we use it everywhere from data onboarding through to implementation of complex algorithms trading the markets. We’re happy we made that choice as we’ve seen an explosion in Python since; its breadth, portability and ease of extension have meant that it’s become the lingua franca for anyone doing data science at scale. This, coupled with its open-source nature, has led to the emergence of collaborative and community-driven development of specialised tools for quant and financial data analytics.
Indeed, choosing Python means we’re able to leverage a rich ecosystem of tools built to solve problems for quantitative data science at scale.
One of the most popular tools at our disposal is Pandas, a powerful data manipulation library in Python. Pandas provides data structures and functions for efficiently handling and analysing structured data, making it a crucial instrument for quantitative researchers and engineers. With Pandas, users can easily clean, transform and analyse financial data, perform statistical calculations and create visualisations.
It’s also the tool that introduces an intuitive two-dimensional data structure, the DataFrame. The DataFrame is especially important as it is often the base unit of analysis in modern data science workflows.
Another important tool in this domain is NumPy. NumPy is a fundamental package for scientific computing in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays. Quantitative researchers and engineers often use NumPy for numerical computations and mathematical modelling in finance.
Turning to other libraries, we would also highlight Scikit-learn, a machine learning library for Python which provides simple and efficient tools to enhance data analysis and modelling. It’s specialised for various machine learning algorithms, provides functionality for classification, regression, clustering and more. Users often employ its features for data preprocessing, feature selection and model evaluation.
Being rooted in the Python ecosystem means that all these tools have high degrees of interoperability, making it easy to build bespoke extensions and maintain. The system solves the problem of generating value from data in an efficient way. The substance that flows through the system is data — and the form it takes is DataFrame, we might think of it as the binding agent.
The problem faced by individuals, teams and organisations is how to scale DataFrames without losing any of the benefits of interoperability, invisible tooling and organisational efficiency.
Scaling the DataFrame: ArcticDB
This is a problem we were faced with at Man Group and what led to us developing ArcticDB — quant finance database — designed with our principles of technology and people-powered systems in mind.
Solve the problem
The problem ArcticDB addresses is making data highly available, with near-zero footprint and minimal cognitive load.
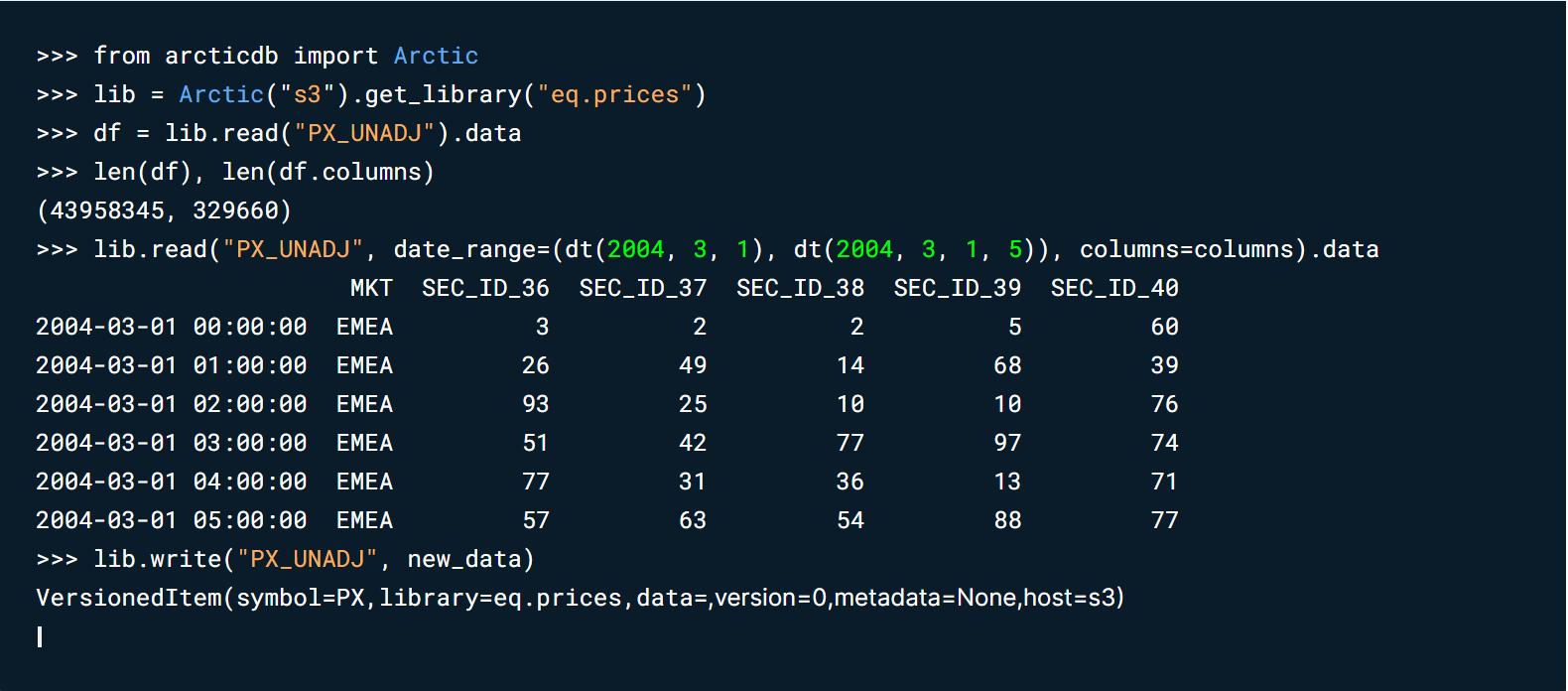
In modern quantitative data science it’s crucial to have the ability to work with huge amounts of data: a typical dataset might be many hundreds of thousands of columns wide, and billions of rows deep. Frustratingly, a DataFrame without ArcticDB maxes out at a size which is orders of magnitude smaller than that. We’ve also built in smarts to optimise ArcticDB for the complexity of financial data.
Be interoperable
ArcticDB fits seamlessly into the Python data science ecosystem, expanding on the concept of the DataFrame as a common thread.
ArcticDB was designed to swiftly make data available in existing systems, without a complex refactoring of code
Scale efficiently
ArcticDB operates on the edge, it’s a client-side database and installable with one command. It’s truly serverless in the sense that end users can run it on their own machines (physical or virtual) without having to provision a dedicated database server. The C++ engine deals with all of complexities of retrieving data for users without them having to think about it, they just send the command in Python.
We designed ArcticDB to scale without the need for dedicated infrastructure or administration. It is also designed to be production-ready, it powers front office analytics at Man Group and is being used across other financial services organisations.
Invisible tooling
The most important factor we considered when designing ArcticDB was that it should be a tool that enables our people.
The first step in the design of the Python API and the other important element is minimising cognitive load. ArcticDB makes data highly available without the user having to switch context; it brings huge amounts of data back in format that’s instantly usable — the DataFrame. This means users can spend more time focussed on their data science — speeding up the time to value.
Nick Clarke head quant for ArcticDB:
I’ve been working for years as a quant and have used lots of different database technologies. When I tried ArcticDB I immediately realised it was different. I am passionate about it, because it takes away the pain of dealing with the data. That leaves me free to focus on generating value with better models and ultimately, solving business problems.
Conclusion
Effective systems in modern quantitative data science need to be mindful of both technology and people. When selecting the right toolkit for a system it’s important to consider all the factors outlined above: tackling the problem with the right solution, prizing interoperability, scaling efficiently and the invisibility of tools — combined, these make for technology that is an extension of a team, rather than an impediment.
Through the use of the Python Open Source ecosystem, it’s possible to build a system that goes some way in achieving that. But in order to truly achieve the flow state demanded in modern financial data workflows, we must pay attention to the re-use, sharing and renewal of data. The base unit of analysis to consider is the DataFrame and solving the challenge of scaling it for the huge volumes and complexity of data we use in addressing modern business problems.
ArcticDB is our answer to DataFrames-at-scale challenge — we’ve found it to be transformative in the way we do data science and we’re privileged to be able to share it with all.
Why ArcticDB? Our answer to high-volume DataFrame processing in Quant Finance

Abhi Thakur
Jan 5, 2024

Aug 19, 2025
Unlocking the Winning Formula: Sports Analytics with Python and ArcticDB
Discover how Bill James' famous Pythagorean Won-Loss formula predicts team success. This deep dive uses ArcticDB to uncover key insights for winning.

Mar 21, 2025
Our Man Group case study: Generating alpha and managing risk at petabyte scale using Python.
This blog explores how ArcticDB is transforming quantitative research by overcoming the limitations of traditional database systems.

Elle Palmer